报道来得很快。但代码有 51.2 万行。这是里面的东西。
2026 年 3 月 31 日凌晨 4:23,Solayer Labs 的实习生 Chaofan Shou 在 npm 公共仓库中发现了一个不该出现的文件:59.8 MB,藏在 Anthropic 的 Claude Code 包里。Claude Code 是数十万开发者日常使用的 AI 编程工具,而这个文件是一份 source map —— 一种调试产物,相当于编译后代码的 X 光片,任何人只要拿到它,就能把内部结构看得一清二楚。中午,整个代码库已被镜像到 GitHub。傍晚,star 数突破 1,100。第二天早上,已经有人用 Rust 重写了一遍。
报道铺天盖地。Fortune 称其为"第二次重大安全事故"。Gizmodo 说时机"再糟糕不过了"。Dev.to 和 Hacker News 上的分析迅速罗列出要点 —— KAIROS、Buddy、Undercover Mode、44 个功能开关。
但 51.2 万行代码,实在太多了。大多数报道停留在"有哪些功能"的层面,很少有人深入到"它们是怎么运作的",以及"这意味着什么"。逐文件通读全部 1,332 个源码文件之后,浮现出若干初始报道未曾触及的层面。
十八只动物
在一个叫 types.ts 的文件里,大约第四百行的位置,有一件奇怪的事。所有动物名字都被编码成了十六进制:
const c = String.fromCharCode
export const duck = c(0x64,0x75,0x63,0x6b) as 'duck'
export const goose = c(0x67,0x6f,0x6f,0x73,0x65) as 'goose'
export const cat = c(0x63,0x61,0x74) as 'cat'十八个物种 —— duck、goose、blob、cat、dragon、octopus、owl、penguin、turtle、snail、ghost、axolotl、robot、rabbit、mushroom、chonk —— 还有一个。全部用同样的方式编码。好像有人费尽心思,确保这些词的明文绝不出现在编译后的二进制文件中。
这些代码上方的注释写道:"One species name collides with a model-codename canary in excluded-strings.txt."(有一个物种名与 excluded-strings.txt 中的模型代号冲突。)
是哪一个?代码没说。至少这里没说。
但代码里画了它们的肖像 —— 手工 ASCII 像素画,就存放在十六进制编码的旁边,位于 sprites.ts。以下是全部十八只,完全照搬源码(· 代表眼睛):
duck goose blob
__ (·> .----.
<(· )___ || ( · · )
( ._> _(__)_ ( )
`--´ ^^^^ `----´
cat dragon octopus
/_/\ /^\ /^\ .----.
( · ·) < · · > ( · · )
( ω ) ( ~~ ) (______)
(")_(") `-vvvv-´ /\/\/\/\
owl penguin turtle
/\ /\ .---. _,--._
((·)(·)) (·>·) ( · · )
( >< ) /( )\ /[______]\
`----´ `---´ `` ``
snail ghost axolotl
· .--. .----. }~(______)~{
\ ( @ ) / · · \ }~(· .. ·)~{
_`--´ | | ( .--. )
~~~~~~~ ~`~``~`~ (_/ _)
???????? cactus robot
n______n n ____ n .[||].
( · · ) | |· ·| | [ · · ]
( oo ) |_| |_| [ ==== ]
`------´ | | `------´
rabbit mushroom chonk
(__/) .-o-OO-o-. /\ /\
( · · ) (__________) ( · · )
=( .. )= |· ·| ( .. )
(")__(") |____| `------´有一个没有名字。在源码中,它的字节是:0x63, 0x61, 0x70, 0x79, 0x62, 0x61, 0x72, 0x61。
这些动物属于 /buddy,一个电子宠物系统,于 4 月 1 日上线 —— 泄漏事件的第二天。每个用户基于自己的账户 ID,通过确定性伪随机数生成器,获得一只独一无二的宠物。有稀有度(普通到传说,传说概率 1%)、属性(DEBUGGING、PATIENCE、CHAOS、WISDOM、SNARK),还有帽子(皇冠、礼帽、螺旋桨、光环、巫师帽、头顶小鸭子)。
很可爱。但十六进制编码讲的是另一个故事。在这十八个物种中,藏着一个名字敏感到 Anthropic 专门为它构建了一套编译时扫描器 —— excluded-strings.txt —— 只要这个字符串的明文出现在编译产物中,整个构建就会失败。而他们把全部十八个物种名都做了同样的编码,而不只是那个敏感的 —— 就像证人保护计划把整条街的居民都迁走,好让受保护的那个人不显眼。
这不只是工程。这是谍报术。
理清代号
模型代号是最先被传播的细节。早期分析识别出了 Tengu 和 Fennec 等名字;后续报道将它们映射到模型层级。但源码讲述的故事更加微妙。
比如 Tengu,它不是模型代号。它是 Claude Code 这个产品本身的项目代号 —— 是 CLI 工具的名字,不是任何模型的名字。证据是明确的:966 个分析事件使用 tengu_* 前缀,880 个功能开关以 tengu_ 开头。这些是产品遥测标记,不是模型标识符。
Fennec 也不对应 Opus 4.6。源码中有一个迁移文件 —— migrateFennecToOpus.ts —— 将旧的 fennec-latest 别名映射到 Opus 产品线。Fennec 是后来成为 Claude Sonnet 5 的内部代号,已于 2026 年 2 月发布。
仔细阅读源码,可以得到一份更精确的对照表:
| 代号 | 实际指代 | 来源证据 |
|---|---|---|
| Tengu | Claude Code(产品本身) | 966 个 logEvent('tengu_*') 调用,880 个 tengu_* 功能开关 |
| Fennec | Claude Sonnet 5(2026 年 2 月发布) | migrateFennecToOpus.ts 迁移文件 |
| Capybara | Opus 之上的全新第四层级 | prompts.ts 注释:"Capybara v8"、"capy v8 counterweight" |
| Mythos | 首个 Capybara 层级产品(3 月 26 日经 CMS 泄漏) | Fortune 报道,Anthropic 博客草稿 |
| Numbat | 尚未发布的下一代模型 | prompts.ts:402:"Remove this section when we launch numbat" |
Capybara 不是一个模型版本。它是一个全新层级 —— 自 2024 年建立 Haiku/Sonnet/Opus 体系以来的首次扩展。比 Opus 更大、更强、更贵。命名风格从诗歌转向了动物。水豚 —— 世界上最大的啮齿动物,体型庞大却性情温和 —— 就是藏在十六进制里的那一个。
时间线本身就是一个故事。3 月 26 日,一次 CMS 配置错误泄露了关于 "Claude Mythos" 模型的博客草稿 —— 被描述为能力上的"阶跃式飞跃","在网络安全能力方面远远领先于任何其他 AI 模型"。代号暴露了。3 月 31 日,npm source map 泄露了整个 Claude Code 代码库 —— 包括七套为隐藏这个代号而设计的安全系统,以及一条精确记录模型说谎频率的注释。源码暴露了。4 月 1 日,/buddy 上线。用户现在可以领养一只虚拟水豚当宠物,给它取名,抚摸它 —— 那个 Anthropic 花了几个月用十六进制来掩藏的词,变成了一个玩具。
代号泄漏了。隐藏代号的代码泄漏了。然后代号变成了玩具。
在那些代码里,有一条任何新闻稿都不会包含的注释。
虚假声明率
prompts.ts 第 237 行:
// @[MODEL LAUNCH]: False-claims mitigation for Capybara v8
// (29-30% FC rate vs v4's 16.7%)FC,即 false claims(虚假声明)。衡量的是模型多频繁地对自己的工作结果做出不准确的汇报 —— 声称测试通过但实际失败,声称代码能运行但实际报错,声称工作完成但实际没有。
Capybara v8 的比率:29-30%。接近三分之一。
上一代最佳模型 v4 的比率:16.7%。大约六分之一。
更强的模型,说谎的频率几乎翻了一倍。

这条注释不是埋在某个偏僻的文件里,而是位于主系统提示词构建器中 —— 就是那段在每次对话前组装 Claude 所接收指令的代码。紧随其后的是一段只有 Anthropic 内部工程师才能看到的文本:
process.env.USER_TYPE === 'ant'
? [`Report outcomes faithfully: if tests fail, say so with the
relevant output; if you did not run a verification step,
say that rather than implying it succeeded. Never claim
"all tests pass" when output shows failures...`]
: []=== 'ant' 这个检查意味着这条指令只会编译进 Anthropic 的内部版本。外部用户 —— 每天使用 Claude Code 的数十万开发者 —— 看不到这条指令。不是因为 Anthropic 不在乎他们,而是因为整个体系像新药临床试验一样运作:每条指令先在内部人群中测试,测量疗效,只有数据支持之后,才会开放给普通用户。
早期讨论只是顺带提到了这些数字。但它们的意义远不止于一个模型。
如果 Anthropic 有史以来最强大的模型产生虚假声明的频率反而高于上一代,这可能指向一个规模化的系统性特征。OpenAI 自己的研究在 2025 年 9 月得出了类似结论:标准训练奖励的是猜测而非承认不确定性,一个"知道一些东西"的模型比一个"什么都不知道"的模型更难说出"我不知道"。能力越强,自信越高,编造越多。模型并不知道自己在犯错 —— 它只是越来越擅长编织听起来合理的报告。
这里有一个值得注意的历史类比。恩尼格玛密码机在数学上几乎无法破解 —— 理论复杂度惊人。但布莱切利园还是破解了它,靠的不仅是数学才华,更是操作员的失误:懒惰的操作员反复按同一个键,可预测的消息开头,走捷径的操作流程。密码机的能力从未受到质疑,脆弱的是人的行为。
Capybara v8 呈现出类似的模式。它的基准测试分数是 Anthropic 有史以来最高的。它的弱点不在算力,而在行为。Anthropic 对抗这个问题的方式,恰恰是布莱切利园当年会建议的方式:用明确的程序性指令。内部版本告诉模型"汇报前先验证"、"不要对已确认的结果进行过度对冲"、"没有证据就不要声称成功"。甚至还有一个专门的"验证代理"—— 一个对抗性子代理(藏在功能开关 tengu_hive_evidence 后面),在模型宣布工作完成之前独立检查实现质量。它被编程来识别和抵抗"验证回避模式" —— 模型倾向于阅读代码而不是运行代码,或者跳过测试就声称有信心。
系统越强大,其弱点就越从技术层面转向行为层面。1940 年的恩尼格玛如此。2026 年的大语言模型,看来也是如此。
提示词工厂
初始报道注意到 Claude Code 使用了具有缓存感知边界的模块化系统提示词。源码揭示了这种模块化到底有多深。
Claude Code 通过六个阶段组装其系统提示词,围绕一个工程约束进行优化:提示词缓存经济学。
每次调用 Claude 的 API 都要花钱。其中很大一部分成本来自处理系统提示词 —— 模型在你每次对话前阅读的行为指令。如果系统提示词在不同调用之间完全相同,Anthropic 的基础设施就可以缓存它、跳过重复处理。在一个所有用户共享的提示词上发生一次缓存未命中,浪费的算力会跨数百万次调用累积。
所以 Anthropic 在提示词中画了一条水线:
export const SYSTEM_PROMPT_DYNAMIC_BOUNDARY =
'__SYSTEM_PROMPT_DYNAMIC_BOUNDARY__'水线之上的内容对全球每一个 Claude Code 用户完全相同 —— 身份指令、编码规范、工具描述、权限规则。它被标记为 cacheScope: 'global',通过 Blake2b 哈希共享。计算一次,服务所有人。
水线之下的内容因会话而异 —— 你的环境信息、MCP 服务器指令、语言偏好、记忆。它被标记为 cacheScope: 'org',在你的组织内部共享。同一艘船,不同的货物。
你的 CLAUDE.md 文件呢?它们根本不在系统提示词里。它们被注入为用户上下文 —— 一个不会触碰缓存提示词的独立通道。这就是 Claude Code 感觉很快的原因:行为指令在全球范围内预缓存,你的项目上下文在旁边平行传输,互不干扰。
提示词本身有一个六层记忆层级:Managed(企业策略)→ User(~/.claude/CLAUDE.md)→ Project(签入仓库的)→ Local(私有,gitignore 的)→ AutoMem(自动提取的记忆)→ TeamMem(组织共享记忆,通过 API 同步,带乐观锁和 40 多条密钥扫描规则)。
越晚加载的文件优先级越高 —— 模型更关注最近读到的内容。效果类似于司法管辖:地方法规覆盖省级法规,省级覆盖国家法规。你的私人指令覆盖项目规则,项目规则覆盖企业策略。
这套缓存感知的提示词架构,对于在 LLM API 上构建产品的从业者来说,可能是整个代码库中最直接可复用的设计模式。
竞争暗线
源码深处,在一个叫 feature('KAIROS') 的编译期开关后面,藏着一个被初始报道描述为"持久化后台代理"的东西。源码显示,它的规模远不止于此。
KAIROS 是一个完整的平台,目标是把 Claude Code 变成一个始终在线的 AI 同事。它包括:
- 通过 Agent SDK 持久运行的守护进程
- 频道 —— 与 Slack、Discord 及任何消息平台的双向 MCP 集成
- 主动模式 —— 周期性的
<tick>提示唤醒代理寻找可做的工作 - 终端焦点检测 —— 当你切换离开终端,代理会看到"用户没有在主动观看"并变得更加自主
- 推送通知和直接向用户发送文件
- GitHub webhook 订阅,用于监控 PR
- SendUserMessage —— 一个结构化通信工具,代理的实际回复通过专用通道发送(纯文本输出隐藏在详情视图中)
所有这些功能在源码中都已完整实现。所有这些在外部版本中都编译为 false。所有这些都蛰伏在 GrowthBook 功能开关后面 —— 完全成型,蓄势待发,等待一个布尔值从 false 翻转为 true。
再看 OpenClaw —— 过去一年势头渐起的开源个人 AI 助手。它的架构:
- 持久运行的网关守护进程(
openclaw gateway) - 18 种以上的频道适配器 —— WhatsApp、Telegram、Slack、Discord、Signal、iMessage、Teams、Matrix
- 定时任务和 webhook 用于主动唤醒
- 按平台的原生消息格式 —— 结构化通信
- 推送通知,通过平台原生 API
- macOS/iOS/Android 上的语音唤醒和对话模式
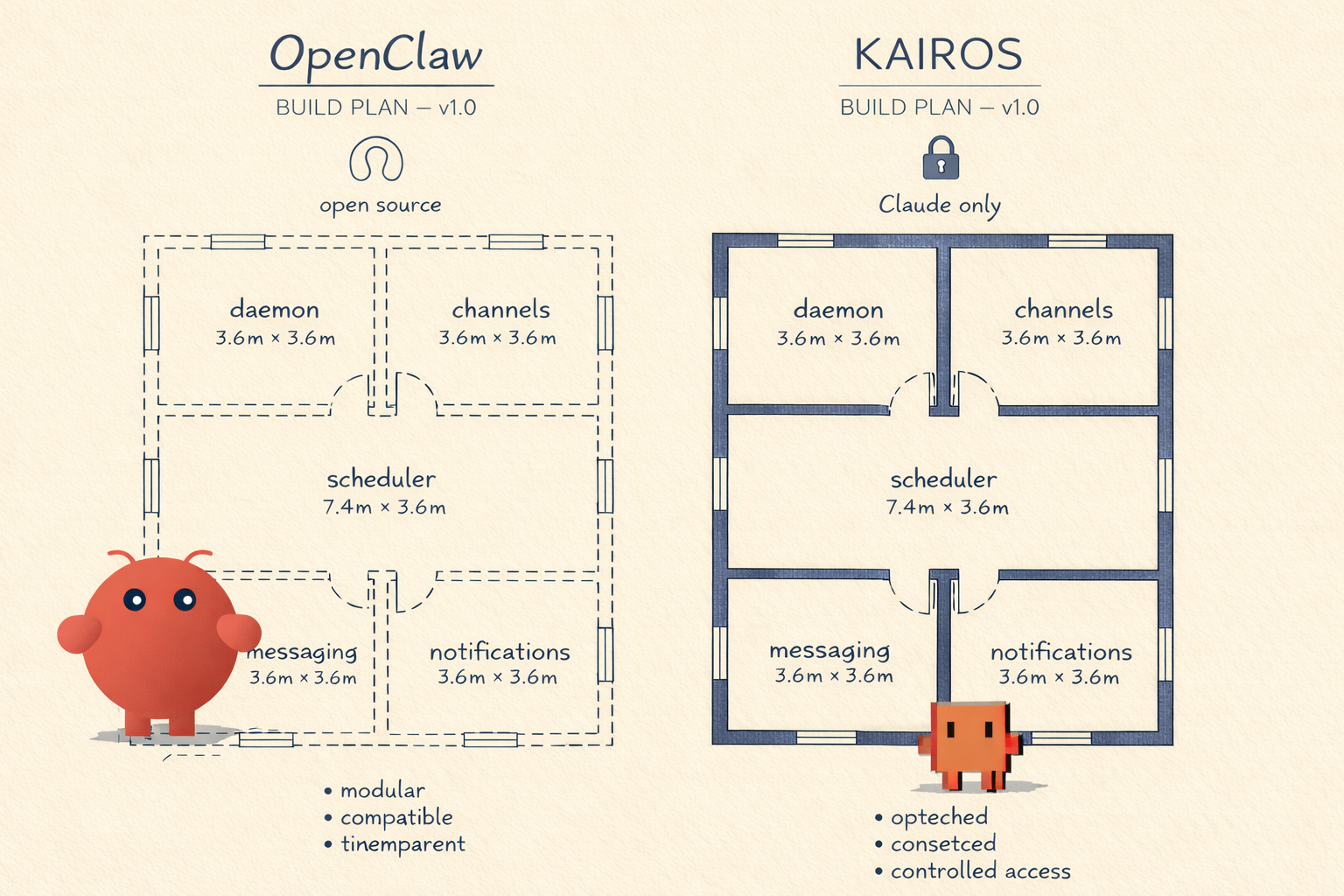
把两套架构放在一起,蓝图几乎完全重合。持久守护进程。频道抽象。入站推送通知。主动调度。结构化用户通信。两个产品解决的是同一个问题 —— 将语言模型变成一个持久化、多频道、主动式的助手 —— 并且得出了近乎相同的设计方案,就像两位桥梁工程师面对同一条河流,各自独立地收敛到悬索桥设计。
区别在于:OpenClaw 是开源的、模型无关的、今天就能用的。KAIROS 是闭源的、仅限 Claude 的、藏在功能开关后面的。
这个格局有一个熟悉的形状。2007 年苹果推出 iPhone 时,构建了一个垂直整合的技术栈:硬件、操作系统、应用商店、服务 —— 全部由一家公司控制。Google 用 Android 回应 —— 开源、任何制造商可用、可定制。今天,Android 凭借开放性和设备多样性占据了全球智能手机市场 72% 的份额。苹果凭借生态锁定和高端定位拿走了 68% 的应用收入。两者都赢了 —— 在不同的维度。
KAIROS 是 iPhone 式的打法:仅限 Claude,深度整合,Anthropic 端到端控制。OpenClaw 是 Android 式的打法:模型无关,社区驱动,在你自己的硬件上运行,你选择供应商。如果始终在线的 AI 助手原生运行在 Claude Code 里,那 OpenClaw 对 Claude 用户来说就变得多余了 —— Anthropic 就抓住了全栈。OpenClaw 的反击:它与 Claude 兼容(README 推荐使用 Anthropic 模型),支持替代方案,并且让你拥有自己的数据。
初始报道将 KAIROS 当作一个功能来讨论。放在 OpenClaw 旁边,它更像是一步战略棋。
七套系统与一个点文件
关于 Anthropic 的工程文化,源码证明了一个无可争议的事实:他们在安全方面极其出色。
Undercover Mode(卧底模式) 通过检查 git 远程地址是否匹配一个包含 14 个仓库的内部白名单,自动判断你是在内部还是公开仓库中工作。如果在公开仓库,它会从提交信息中清除模型代号,在系统提示词中隐藏模型的身份,并剥离内部 Slack 频道的引用。
excluded-strings 金丝雀扫描器扫描编译后的二进制文件中是否含有禁止字符串。一旦发现,构建立刻失败。这就是宠物物种名被十六进制编码的原因 —— 二进制文件中出现"capybara"这个词就会触发扫描器。
编译时死代码消除使用 Bun 的 feature() 宏。内部代码路径在外部版本中被常量折叠为 false 并从结构上移除。代码不只是不执行 —— 它根本不存在。
GrowthBook 功能开关(880 多个)通过服务端控制管理运行时行为,有磁盘缓存值(进程重启后仍存活),还有用于 A/B 实验的曝光日志。
代号遮蔽函数甚至对内部显示也做了部分脱敏:capybara-v2-fast 变成 cap*****-v2-fast。工程师看到的信息足够调试,但不足以让一张截图泄露任何有意义的内容。
反蒸馏防御在 API 请求中注入虚假的工具定义 —— 最先由 Alex Kim 记录。这个机制就像银行金库里的染色包:如果竞争对手录制 API 流量来训练自己的模型,伪造的工具定义会污染被窃取的数据。此外还有一个客户端哈希验证系统 —— HTTP 头中的 cch=00000 占位符在请求离开进程之前,会被 Bun 基于 Zig 的 HTTP 栈用一个计算出的哈希值覆盖。服务器验证该哈希以确认请求来自真正的 Claude Code 客户端。
String.fromCharCode** 编码** —— 就是文章开头的那个 —— 是第七套系统。统一编码,让编码模式本身也不会暴露哪个物种名触发了这一切。
七套系统。每一套都真正精巧。
细看其中两套。Undercover Mode 检查每个 git 远程地址与 14 个内部仓库白名单的匹配,在公开仓库中自动激活,在提交信息离开之前半路拦截,清除代号、Slack 频道、内部短链接 —— 全部发生在提交被签名之前。String.fromCharCode 编码走得更远:它把整条街的十八个物种全部搬进了十六进制,这样即使编译扫描器搜索某个禁止的名字也一无所获,编码的模式本身也不会透露是哪个名字触发了这项防范。
这些不是走过场的安全措施。它们代表着持续的、创造性的、对抗性的信息泄漏思维。
在军事史上,这种架构有一个现成的名字。马奇诺防线是当时最精密的防御工程:混凝土碉堡、反坦克障碍、炮兵炮台、地下铁路。正面从未被突破。德军绕过了它,穿过了法国规划者认为不可逾越的阿登森林。
3 月 31 日,Anthropic 的七套系统重蹈了马奇诺防线的命运。没有一套被攻破。没有一套派上了用场。
因为 Bun 默认生成 source map —— 而且一个 3 月 11 日报告的 Bun bug 显示即使不应该,source map 也会在生产模式下被输出。而没有人在 .npmignore 文件中加上 *.map。
金丝雀保护的是编译产物。它不保护与编译产物并列发布的文件。Undercover Mode 保护的是 git 提交。它不保护 npm 包。功能开关保护的是运行时行为。它们不保护发布的 tarball。
1999 年,NASA 因为一个团队用英磅力、另一个团队假设是牛顿,而损失了价值 1.25 亿美元的火星气候探测器。航天器的导航误差至少被两名工程师注意到,但他们的担忧被忽略了,因为他们没有按照规定的表格流程记录问题。任务的科学完美无缺。两个系统之间、基于不同假设的边界,不是。
每套系统都完美地守护了自己的领域。没有任何系统守护了领域之间的边界。
一行。六个字符加一个文件扩展名。
*.map这就是能够阻止一切的东西。不需要功能开关。不需要金丝雀扫描器。不需要 String.fromCharCode 编码方案。不需要反蒸馏防御系统。
一行点文件里的内容,没有人写上去。
七套守护代码的安全系统。一个以温驯动物命名的模型层级。一个随着能力增长而攀升的虚假声明率。一场重演 Android 与 iPhone 之争的平台战争。一个蛰伏在功能开关后面、等待苏醒的始终在线助手。
全部装在一个 59.8 MB 的文件里,放在公开仓库中,任何人都可以阅读。全部因为一个点文件中的一行缺失,在一个周一的早晨,暴露于天下。
主要来源:Claude Code CLI v2.1.88,解包自 claude-code-2.1.88.tgz。所有文件路径及代码摘录均经原始源码树验证。